
1. 서론 – 세상을 뒤흔든 2012년의 한 편의 논문
2012년 NeurIPS(당시 NIPS)에서 발표된 “ImageNet Classification with Deep Convolutional Neural Networks”, 일명 AlexNet 논문은 현대 딥러닝 열풍의 기폭제였다. 1,000 개의 클래스로 이뤄진 ImageNet ILSVRC‑2010에서 Top‑5 오류율 17.0 %를 기록하며 당시 2등보다 10 %p 가까이 앞서는 압도적 성과를 냈다. 무엇보다 “GPU + 깊은 CNN + ReLU + Dropout”이라는 조합이 컴퓨터 비전의 패러다임을 전면 교체했다.

“이 논문이 없었다면 오늘의 ‘딥러닝 시대’는 5년은 늦게 왔을 것” — Geoffrey Hinton, 2018 인터뷰 중
2. 시대적 배경 – 왜 ‘딥 CNN’이 필요했을까?
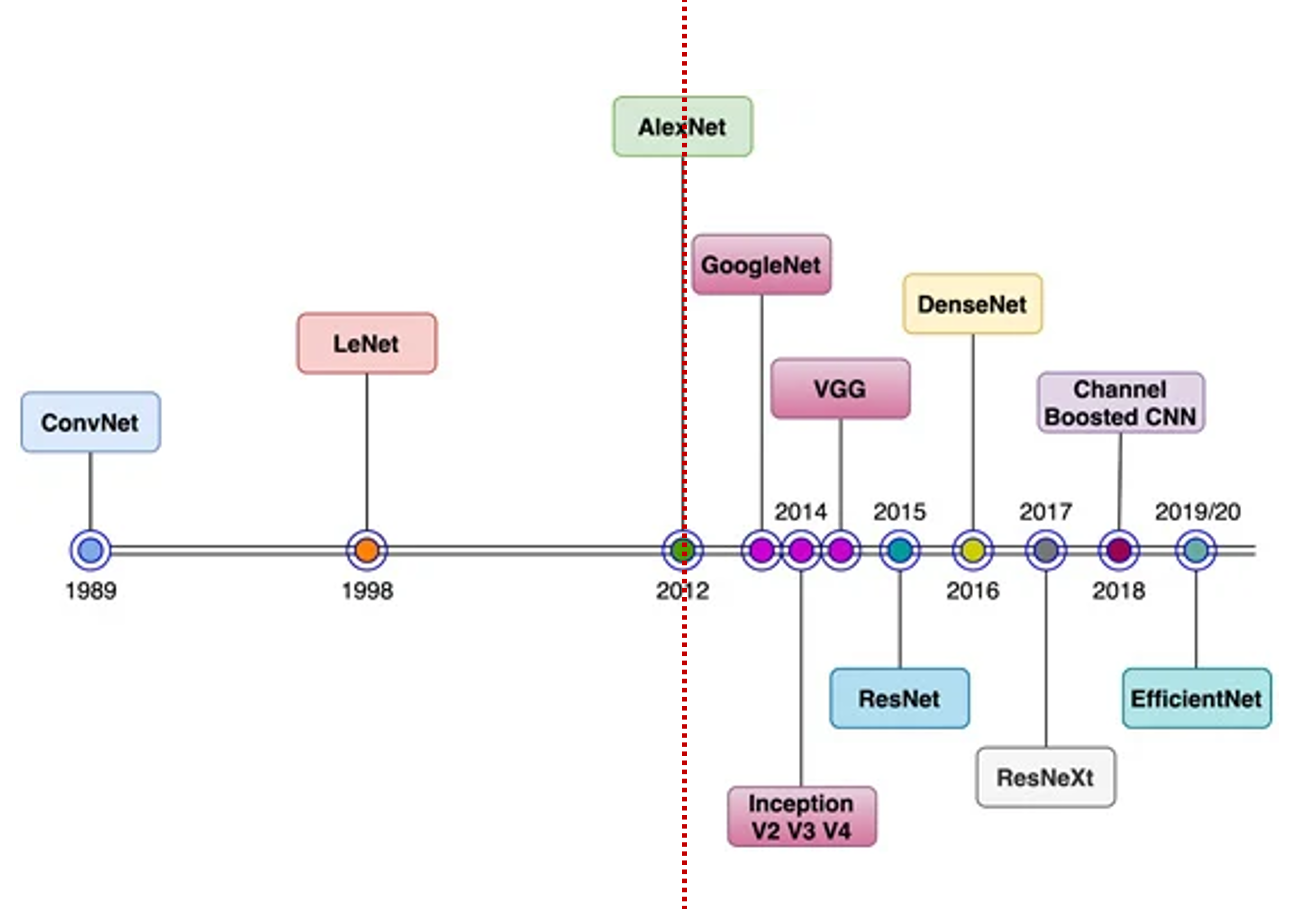
| 연도 | 모델명 | 주요 특징 및 기여 | 한계 |
| 1989 | ConvNet | 최초의 CNN 구조, 숫자 인식 등에 적용 (LeCun) | 연산 자원 부족으로 복잡한 문제에 한계 |
| 1998 | LeNet-5 | MNIST 숫자 분류에서 강력한 성능 | 고해상도·다중 클래스 이미지에는 적용 어려움 |
| 2012 | AlexNet | GPU 사용, ReLU, 드롭아웃 도입, ImageNet 우승으로 딥러닝 붐 촉발 | 필터 크기 큼(11x11), 파라미터 많고 연산량 큼 |
| 2014 | GoogleNet (Inception v1) | 다양한 크기의 필터를 병렬 적용(Inception Module), 연산량 감소 | 구조 복잡, 튜닝 어려움 |
| 2014 | VGG-16/19 | 3x3 필터 반복으로 깊은 구조 구성, 단순하고 직관적 | 파라미터 수 매우 많음(약 138M), 느리고 무거움 |
| 2015 | ResNet | Residual 연결로 gradient vanishing 문제 해결, 152층 학습 가능 | 구조는 간단하지만 계산량 여전히 많음 |
| 2016 | Inception v2/v3/v4 | 구조 개선으로 정확도 상승, factorization 사용 | 여전히 복잡한 구조, 실무 적용 어려움 |
| 2016 | DenseNet | 모든 레이어를 연결(Dense connection), 피처 재사용 극대화 | GPU 메모리 요구 높고, 학습 속도 느림 |
| 2017 | ResNeXt | 그룹 컨볼루션으로 ResNet보다 더 나은 효율성 확보 | 구조가 더욱 복잡해져서 이해·튜닝 난이도 상승 |
| 2018 | Channel Boosted CNN | 입력 채널을 강화하여 더 풍부한 특징 사용 | 일반화 부족, 실무 적용 예시 적음 |
| 2019/20 | EfficientNet | depth, width, resolution을 동시에 최적화(compound scaling) | 구조 자동 설계로 해석 어려움, 작은 변화에 민감할 수 있음 |
2.1. 전통적인 접근의 한계
| 접근 | 방식한계 |
| 핸드크래프트 피처 (SIFT, HOG, LBP 등) |
- 도메인 전문가의 직관에 의존 - 피처 간 상호작용 학습 불가 |
| 얕은 모델 (SVM, BoF + SPM 등) | - 표현력 부족 - 데이터 규모·클래스 수 증가 시 급격한 성능 저하 |
| 초기 CNN (LeNet 등) | - 작은 이미지셋(MNIST)에선 유효 - 고해상도/다중 클래스 문제엔 컴퓨팅 자원 한계 |
요약: 전통 모델은 복잡한 이미지나 대규모 데이터에 적응하지 못함.
2.2. 기술적 변화와 데이터의 폭발
| 요소 | 설명 |
| ImageNet 등장 (2009~2011) | - 1,500만 장, 22,000개 클래스라는 거대한 라벨링 이미지 데이터셋 출현 - 고성능 학습 모델 요구 폭증 |
| CPU의 한계 | - 당시 대부분 모델은 CPU 기반으로, 연산 속도와 메모리 용량에 심각한 제약 |
| GPU 도입 | - 병렬 연산이 가능한 GPU 등장으로 대규모 신경망 학습 가능해짐 |
요약: 데이터는 늘었는데, 기존 방식으로는 처리 불가능 → 새로운 구조 필요.
2.3. AlexNet의 등장 (2012)
- 2대의 GPU를 병렬로 활용하여 5개의 Conv + 3개의 FC 레이어라는 전례 없는 깊이 실현
- ReLU, Dropout, 데이터 증강 등 현대적 기법 최초 도입
- ImageNet 대회에서 압도적 1위 기록 → 전 세계 주목
결과: AlexNet은 기존 한계를 기술적으로 돌파하고, 딥러닝 시대의 포문을 열었음.
결론
딥 CNN은 단지 모델의 “깊이”를 더한 것이 아니라, 기존 피처 기반 방식의 한계를 넘어서기 위한 필연적인 진화였습니다.
대용량 이미지 데이터의 시대가 도래하고, 기존 얕은 모델로는 이를 다루지 못하게 되면서,
표현력과 추상화 능력이 뛰어난 깊은 신경망(CNN)이 필수적인 해법으로 떠오르게 된 것입니다.
3. AlexNet의 혁신 포인트 6가지
| # | 혁신 요소 | 한 줄 요약 | 오늘날 영향 |
| 1 | ReLU (max(0, x)) | 비포화 활성함수 → 6× 빠른 수렴 | 모든 딥러닝 기본값 |
| 2 | GPU 병렬 학습 | GTX 580 × 2 + CUDA‑ConvNet | CUDA/CuDNN, TPU, ROCm 등 가속 HW 생태계 |
| 3 | Local Response Normalization | “밝기” 정규화 → 일반화 ↑ | BN/IN/LN 개발의 밑거름 |
| 4 | Overlapping Max‑Pooling | s < z 구조로 정보 손실 ↓ | Stride‑2 Conv 대체 등으로 진화 |
| 5 | Dropout (p = 0.5) | FC 층에서 앙상블 효과 | Vision Transformer 등에도 기본 탑재 |
| 6 | 데이터 증강 | 랜덤 크롭 & 좌우 반전 + PCA Color Jitter | RandAugment, Mixup, CutMix로 확장 |
4. 아키텍처 해부 – 8 개의 학습 레이어, 6천만 파라미터

Input 224×224×3
└─ Conv1 11×11, 96 K, stride 4 → ReLU → LRN → MaxPool (3×3, s2)
└─ Conv2 5×5, 256 K(split), stride 1 → ReLU → LRN → MaxPool
└─ Conv3 3×3, 384 K → ReLU
└─ Conv4 3×3, 384 K(split) → ReLU
└─ Conv5 3×3, 256 K(split) → ReLU → MaxPool
└─ FC6 4096 → ReLU → Dropout
└─ FC7 4096 → ReLU → Dropout
└─ FC8 1000 → Softmax- split: 두 GPU 간 커널 맵을 절반씩 분리해 메모리·통신량 최소화.
- LRN: 5개 채널(window) 단위로 활동값 제곱합을 스케일링.
- 전체 파라미터의 95 % 이상이 FC6·FC7에 집중 → 이후 논문(VGG, GoogLeNet)은 이를 1×1 Conv로 치환해 파라미터 효율화.
5. PyTorch로 구현해 보는 Mini‑AlexNet
※ 학습용 데모 — 전체 구조·채널 수를 축소한 경량 버전
import torch
import torch.nn as nn
class MiniAlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 1024),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(1024, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
if __name__ == "__main__":
model = MiniAlexNet(num_classes=10)
print("Parameter count:", sum(p.numel() for p in model.parameters())/1e6, "M")
dummy = torch.randn(4, 3, 224, 224)
out = model(dummy)
print("Output shape:", out.shape)Tip.
- torchvision.models.alexnet(pretrained=True)로 원본 AlexNet 가중치를 즉시 활용 가능.
- 현대 딥러닝 실험에서는 BN, GELU, AdaptiveAvgPool 등으로 대체/개선하기도 한다.
6. 실험 결과 & 성능 분석
| 모델 | Top‑1 | Top‑5 | 연산량(MACs) | 특징 |
| 기존 SIFT+Fisher Vector | 45.7 % | 25.7 % | – | CPU 기반 전통 피처 |
| Sparse Coding (2010 우승) | 47.1 % | 28.2 % | – | 다중 모델 앙상블 |
| AlexNet (2012) | 37.5 % | 17.0 % | 7.2 G | GPU 2대, 5–6 일 학습 |
- Dropout 미사용 시 Top‑1 오류 39 %
- 10‑crop 테스트(4 코너+센터×좌우)로 1.5 %p 추가 개선
오늘날 ResNet‑50은 Top‑1 76 % 수준. 하지만 AlexNet이 20 %p 격차를 한 번에 좁혔다는 역사적 의미는 압도적이다.
7. 후속 영향 – VGG, GoogLeNet, ResNet, 그리고 딥러닝 르네상스
| 연도 | 모델명 | 핵심 기여 및 영향 |
| 2014 | VGG | 3×3 Conv 스택으로 구조 단순화 및 깊이 확장 용이성 확보. 이후 다양한 네트워크의 기반이 됨. |
| 2014 | GoogLeNet (Inception v1) | 연산 효율과 정확도 동시 확보. 파라미터 수를 ≈5M으로 크게 줄이며 ImageNet 우승. |
| 2015 | ResNet | Residual connection 도입 → 152층 학습 가능. 딥러닝 학습의 깊이 한계 극복. |
| 2017 | DenseNet | 모든 이전 레이어와 연결(Dense connection)하여 피처 재사용을 극대화, 효율적 학습 유도. |
| 2020 | Vision Transformer (ViT) | Conv 없이 Attention만으로 이미지 분류 달성. 이후 GPT-4V 등 멀티모달 시대의 시작점. |
AlexNet은 단지 CNN을 성공시킨 것이 아니라, 딥러닝 전체의 퀀텀 점프를 만든 신호탄이었다.
그 이후의 모델들은 표현력, 연산 효율, 학습 안정성을 향해 진화했고, 이는 곧 대규모 언어 모델(LLM)과 비전 트랜스포머로 이어져, 오늘날의 AI 혁신을 가능케 했다.
8. 실무 인사이트 – 2025년에도 유효한 교훈
- 하드웨어‑소프트웨어 코‑디자인: 알고리즘 혁신은 하드웨어 한계를 인식할 때 가속된다. (GPU→TPU, FP16→bfloat16)
- ReLU처럼 단순한 아이디어도 ‘규모’와 만나면 게임체인저가 된다. 작은 프로젝트라도 과감히 적용해볼 것.
- Data > Model: 120 만 장의 대규모 학습 데이터가 없었다면 6,000 만 파라미터 모델은 과적합에서 벗어날 수 없었다.
- Regularization Stack: Data Augmentation → Dropout → Weight Decay → Early Stopping … 다층 방어가 필수.
- Baseline의 힘: 강력한 기본 모델 하나가 연구 커뮤니티·산업계에 끼치는 파급력은 대체 불가.
9. 참고 문헌 & 추천 추가 자료
- Krizhevsky, A., Sutskever, I., & Hinton, G. (2012). ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS.
- Jay Alammar, “Visualizing AlexNet,” jalammar.github.io
- Stanford CS231n (2017) Lecture Notes – CNN Architectures.
- Ilya Sutskever, “CUDA‑ConvNet2 Release Notes,” 2013.
- Distill.pub, “A Guide to Convolution Arithmetic for Deep Learning,” 2016.
- Blog “AlexNet – The Beginning of the Deep Learning Era,” Towards Data Science, 2020.
권장 실습: Kaggle “Dogs vs. Cats” 데이터셋에 torchvision.models.alexnet Fine‑Tuning으로 5‑epoch 만에 97 % Accuracy 달성해보기.
✍️ 맺음말
AlexNet은 ‘CNN의 재발견’을 넘어 딥러닝 패러다임의 대전환을 촉발했다. ReLU 한 줄, Dropout 몇 줄, 그리고 “GPU로 돌리면 된다”는 발상의 전환이 어제의 한계를 오늘의 상식으로 바꿨다. 2025년 오늘, 우리의 코드 한 줄 역시 앞으로 10년의 상식을 뒤흔들 잠재력을 품고 있을지 모른다.

“Don’t be afraid to try something completely different — it might just work.” — Alex Krizhevsky
'논문' 카테고리의 다른 글
| [논문] Playing Atari with Deep Reinforcement Learning (2013) (0) | 2025.10.31 |
|---|---|
| [논문 리뷰] Generative Adversarial Nets (2014) (1) | 2025.09.30 |
| [논문 리뷰] A Fast Learning Algorithm for Deep Belief Nets (2006) (5) | 2025.07.31 |
| [논문 리뷰] Attention Is All You Need (2) | 2025.07.03 |



